檔案內搜尋字串程式 (GREP) 之設計

簡介
GREP 是 UNIX 作業系統下一個由檔案中搜尋指定字串的工具程式,
讓我們用兩種方法來設計這樣子功能的程式,
你將會學到:
-
處理基本的命令列參數
-
檔案開啟、字元讀取、與檔案關閉
-
字串函式使用
-
程式如何記憶比對的狀態 - 狀態圖的使用
-
命令列參數 *.* 或是 ???.?pp 的處理

基本的命令列參數處理
C 程式的進入點是 main() 函式,
作業系統呼叫 main() 函式並將 CPU
的控制權交給以 C 語言撰寫的應用程式,
作業系統在處理操作者的命令,
例如: copy file1.dat file2.dat 時,
通常 copy 是一個可執行的工具程式,
file1.dat 及 file2.dat 則是操作者希望交給 copy.exe
這個執行程式去處理的資料,
作業系統的命令列解譯程式於是將 copy.exe
檔案內的程式載入記憶體,
呼叫其中的 main() 函式,
並將 "copy" "file1.dat" 及 "file2.dat"
這三個字串的位址記錄於指標陣列
char *argv[] 內傳入 main() 函式內處理,
在 int argc 參數內記錄 3,
main() 函式的參數宣告如下:
int main(int argc, char *argv[])
以上例而言,
下列敘述
printf("argc=%d\n",argc);
printf("argv[0]=%s\n",argv[0]);
printf("argv[1]=%s\n",argv[1]);
printf("argv[2]=%s\n",argv[2]);
將列印出
argc=3
argv[0]=c:\cwin95\command\copy.exe
argv[1]=file1.dat
argv[2]=file2.dat
我們要撰寫的 grep 程式的操作方式範例如下:
grep xstring file1.txt
grep "string two" file2.dat
grep xstring file1.txt file2.txt
grep String *.txt
因此我們需要以下列程式觀察一下上面這幾種狀況下程式內究竟看到
argv[] 指標陣列內有什麼樣子的字串?
int i;
for (i=0; i<argc; i++)
printf("argv[%d]=%s\n", i, argv[i]);
檔案開啟、字元讀取、與檔案關閉
-
檔案開啟
fp = fopen(argv[2], "r");
-
字元讀取
c = getc(fp); 或是 iRet = fscanf(fp, "%c", &c);
-
檔案結束測試
EOF 為 stdio 函式庫中定義的常數,
其數值為 -1
-
檔案關閉
字串比對方法
假設操作者希望比對的字串是七個字元的 "xstring",
在程式內當然需要準備至少容納八個字元的字元陣列來存放此字串,
另一方面,
檔案內欲比對的資料在程式內則可以有兩種方法來表示:
在程式內保留相同字元數目的暫存區
此暫存區內儲存最後由檔案內讀出的 8 個字元,
並可利用一迴圈比對兩個字串的內容,
在這樣子的前提之下,
如果一次由檔案內讀出多一點的字元,
例如 128 個位元組,
至記憶體內的字元陣列,
也許處理上比較方便,
例如:
char fileBuf[128];
count = fread(fileBuf, 128, 1, fp);
比對迴圈則可用如下程式:
for (i=0; i<count-strlen(cTargetStr); i++)
{
success = 1;
for (j=0; j<strlen(cTargetStr); j++)
if (fileBuf[i+j] != cTargetStr[j])
{
success = 0;
break;
}
}
注意:
-
上面這個方法在比對時,
檔案中連續兩段資料之間會有幾個字元 (strlen(cTargetStr)-1)
沒有比對完全,
必須保留下來,
如下:
for (i=count-strlen(cTargetStr)-1; i<count; i++)
fileBuf[i-count+strlen(cTargetStr)+1] = fileBuf[i];
下一次讀檔則改為
count = fread(&fileBuf[strlen(cTargetStr)], 128, 1, fp) + strlen(cTargetStr);
-
上面這種方法如果仔細分析的話,
會覺得有一點浪費,
因為在檔案中的每一個字元都可能被上述兩層的迴圈拿出來比較
strlen(cTargetStr) 這麼多次,
實際上檔案中每個字元應該都只需要和最多兩個字元比對就足夠了,
我們用下面的狀態圖來說明這個方法:
程式如何記錄比對的狀態
以搜尋字串 "xstring" 為例,
我們在檔案內衣個字元一個字元往後比對時,
如果出現 'x' 字元的話,
下一個字元只有兩種狀況是我們需要注意的:
一是 's' 字元,
二是 'x' 字元,
若是 'x' 字元的話,
表示前面一次出現的 'x' 字元不是屬於要搜尋字串的一部分,
現在的這個 'x' 字元則可能是我們要搜尋字串的第一個字元,
若是 's' 字元的話,
再下一個字元我們感興趣的是 't' 字元或是 'x' 字元,
以下類推,
我們可以用一個狀態圖來表示:
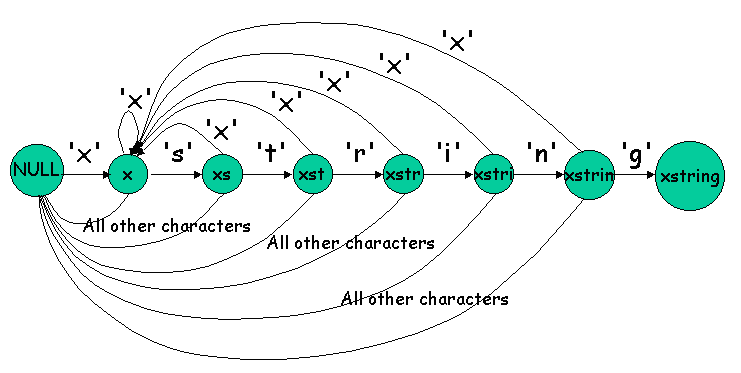
狀態 (States):
上圖中有八個狀態,
分別代表:
-
NULL 代表到目前為止看都沒有看到一個相關的字元,開始狀態
-
前一個字元是 x
-
前兩個字元是 xs
-
前三個字元是 xst
-
前四個字元是 xstr
-
前五個字元是 xstri
-
前六個字元是 xstrin
-
前七個字元是 xstring,結束狀態,
也就是已經找到該字串了。
狀態變換 (State Transitions):
程式運作的狀態會根據檔案下一個字元的內容來改變,
假設目前狀態為 xst,
表示前三個字元分別為 t、s、及 x,
更前面的字元是什麼就不得而知了,
(這當然也說明了為什麼這種狀態圖成為有限狀態的狀態圖了。)
此時檔案中下一個字元可以是任何字元,
其中我們最有興趣的字元是 'r',
若是檔案中的下一個字元真的是 'r' 的話,
則狀態變為 xstr,
愈來愈接近比對成功之路了;
若檔案中的下一個字元不是 'r' 的話,
表示辛辛苦苦才等到的 xst 部分字串又沒用了;
若是檔案中的下一個字元是 'x' 的話,
那還差強人意,
至少可能是另一個開始的機會,
此時狀態變為 x,
現在如果在檔案中出現任何 'r' 或是 'x' 之外的字元的話,
狀態完全重設為 NULL,
一切過去全部一筆勾消,
重新再來。
製作依據狀態圖運作的 GREP 程式
如何以程式表達此狀態圖及狀態的變化呢?
-
一、在程式內如何表達現在是在哪一個狀態?
我們可以很簡單地用一個整數變數來表示,
例如:宣告 int iState; iState 值為 0 表示 NULL 狀態,
1 表示 x 狀態,2 表示 xs 狀態,
3 表示 xst 狀態,
4 表示 xstr 狀態,
5 表示 xstri 狀態,
6 表示 xstrin 狀態,
7 表示 xstring 狀態。
-
二、如果以 c = getc(fp); 由檔案中讀到一個字元的話,
c 該和哪一個字元比對?
if (iState == 0)
{
if (c=='x')
iState = 1;
}
else if (iState == 1)
{
if (c == 's')
iState = 2;
else if (c == 'x')
iState = 1;
else
iState = 0;
}
else if ....
..
else if (iState == 7)
return; // success
或是
switch (iState)
{
case 0:
if (c == 'x')
iState = 1;
break;
case 1:
if (c == 's')
iState = 2;
else if (c == 'x')
iState = 1;
else
iState = 0;
break;
case 2:
...
...
...
case 7:
return; // success
}
這樣子就完成狀態圖轉換的製作了。
-
三、前面兩個步驟是假設和固定字串 "xstring" 來比對,
可是我們需要一個可以和任意字串比對的程式啊,
怎麼辦呢?
狀態的表示
假設要比對的字串放在字元陣列 char cTargetStr[100]; 內的話,
我們可以用 <string.h> 中的 strlen()
函式求出此字元陣列變數內所存放的字串的長度如下:
int length;
length = strlen(cTargetStr);
那麼我們知道現在容許的狀態是從 0 到 length,
程式一開始時狀態 iState 設為 0,
程式結束時如果 iState 為 length 的話就表示搜尋成功,
否則就表示失敗了。
狀態的轉換
在步驟二中我們有許多比較的運算式,
例如:
在目前的情況下應該要變更成:
c == cTargetStr[0], c == cTargetStr[1] ...
真容易,
可是問題又來了,
cTargetStr[] 陣列中第幾個是 'x' 第幾個是 's' 呢?
其實也很簡單,
答案就在 iState 變數上,
iState 為 0 時,
我們最在意的是 c 是否為 cTargetStr[0],
iState 為 1 時,我們最在意的是 c 是否為 cTargetStr[1],...
也就是在任何狀態 iState 下,
我們最在意的是 cTargetStr[iState],
其次我們最在意的是 cTargetStr[0],
步驟二的程式碼於是可以更改為:
if (c == cTargetStr[iState])
iState++;
else if (c == cTargetStr[0])
iState = 1;
else
iState = 0;
if (iState == 7)
return; // success
注意:
這個程式的製作利用狀態圖來簡化程式的邏輯,
這是非常有用的技術,
一定要多想一想。
Hint:其實程式中有時候會使用很多的資料變數來表示程式目前的狀態,
而使用狀態圖時最主要是把這些資料變數轉換為單一的狀態變數,
可以簡化程式的製作過程。
命令列參數 *.* 或是 ???.?pp 的處理
以下面這段程式 testArg 來說,
如果你用 testArg *.* 這個命令來測試的話,
在不同的 shell 環境下會有不同的結果:
int i;
for (i=0; i<argc; i++)
printf("argv[%d]=%s\n", i, argv[i]);
例如在 UNIX csh 下,
*.* 會先被轉換為所有在此目錄下的檔名,
以空格分隔,
直接以 argc, argv 的形式傳入程式中,
但是在 DOS 下則是完全不處理,
直接傳入字串 *.*,
因此必須在程式中處理。
讓我們借助於 TURBO C 中 dir.h 函式庫中的
findfirst(), findnext() 函式、
以及 struct ffblk 結構來處理 * 與 ? 字元,
例如:
/* findfirst and findnext example */
#include <stdio.h>
#include <dir.h>
int main(void)
{
struct ffblk ffblk;
int done;
printf("Directory listing of *.*\n");
done = findfirst("*.c",&ffblk,0);
while (!done)
{
printf(" %s\n", ffblk.ff_name);
done = findnext(&ffblk);
}
return 0;
}
此函式庫中還包括 getcurdir, getcwd, chdir, mkdir, rmdir
等處理資料夾及檔案的函式請自行嘗試,
但是請注意這個函式庫中的函式只能在 DOS 環境下使用。
另外一個處理某一資料夾中檔案的函式庫 dirent.h 則可以在
DOS 及 UNIX 環境下使用,
這個函式庫中包括
opendir, closedir, readdir, 及 rewinddir 等等函式,
請參考 TURBO C 線上說明之範例。
