字串

簡介
字串是一連串字元的集合體,
在以文字界面為主的程式中使用地非常頻繁,
C 語言中並沒有一種基本型態叫做字串。
並不是因為它不常用或是不重要,
而是這種資料和字元陣列的差異很小,
同時在程式語言內支援這種型態的話,
意謂著同時也需要支援這種型態的基本運算、
還有型態的轉換,
C 語言為了維持一個很小的核心
(以便編譯器可以迅速地移植到不同的硬體系統上),
因此並沒有把字串視為基礎型態。

字元陣列
一個字元陣列提供了字串基本的存放空間,
例如:
可以存放 100 個字元 (位元組),
不過這並不是完整的資料體,
在 str 陣列變數中可以存放最多 100 個字元,
可以只放 50 個字元,
也可以通通都不放,
這和其它的基本型態變數不太一樣,
一個 int 型態的變數,
不管怎樣都可以把它拿來當作整數使用並參與任何的運算,
但是一個放了不知道幾個位元的字元陣列要如何來使用卻是一個很大的問題?
在設計程式語言的時候 (請注意我們不是在談設計程式的時候),
最簡單的解決方法是把字元陣列資料 str 配對一個整數變數 count 來使用,
不過這樣子變成程式要記著資料 str 及 count 之間的對應關係,
除非使用 struct 自定資料型態,
否則不見得是一個好方法。
第二個方法是強制在字串結尾加一個結束字元,
例如 '\0' 字元是一個一般字串裡不會出現的字元,
把它放在字串的最後,
如此便可分辨出字串到底有多長,
例如字串 "Hello" 在記憶體內便存為
'H' 'e' 'l' 'l' 'o' '\0',
空白字串 "" 在記憶體內便存為 '\0',
如此 100 個字元的陣列最多只能存放 99 個字元的字串。
這樣子做還有一點點的問題,
就是在寫程式的時候沒有辦法事先知道資料字串的長度,
必須在 CPU 執行的時候一個位元組一個位元組地讀下去以後,
讀到 '\0' 的時候 CPU 才知道究竟有多少個位元組,
需要配置多少的記憶體來容納它、
迴圈必須做多少次...,
可以說是比較沒有效率的一種方式。
第三種方式是將字元個數存放在字串陣列的最前面兩個位元組或是四個位元組,
其它部分則依序存放字元資料,
這種方式的最大問題是資料的內容與資料型態的不符合,
必須背著程式設計者偷偷地做一些事情,
因此程式語言中必須要有支援這種型態的各種特殊運算,
另外這種方法和第一種方法一樣,
都會有最大字串長度受限於記錄長度的這個變數的問題。
C 語言中採取第二種方式來表達字串,
而以 string.lib 中一些函式來支援基本的字串運算,
例如:strcpy, strcat, strrev, strlen, strcmp 等等,
另外在所有的函式庫中只要有需要字串的地方,
也都使用這種 "約定俗成" 的方式來處理字串,
例如:在 libc.lib 中的 printf(const char *, ...) 或是
scanf(const char *, ...) 函式,
函式內在處理第一個字元陣列變數的時候,
就是認為陣列內容由第一個字元一直延續到出現 '\0' 字元的地方結束。
這是程式在被 CPU 執行的時候,
程式的邏輯必須保證此字元陣列中一定要有 '\0' 字元的出現,
編譯器的工作是進行在程式沒有被執行之前的文法檢查,
它完全沒有辦法幫你檢查這件事的。
字串常數
字串雖然不是基本型態,
但是因為使用量太過頻繁,
在 C 程式語言中,
就像任何其它基本型態的資料一樣,
替它定義了字串常數,
其文法為:
"string constant"
"字串常數"
""
字串常數在程式中的型態為
也可以寫成 const char *,
任何語法上可以使用 char const * 的地方都可以使用字串常數,
例如:
char *ptr = "Hello";
xptr = "What";
printf("What %d %f\n",...);
scanf("%f",....);
strcpy(x, "Hello");
注意:
-
字元陣列的初始化時所使用的字元常數並不是解釋為陣列指標常數,
例如:
因此不可以用
char *ptr = "Hello"
char x[10] = ptr;
來取代,
實際上的意思是
char x[10] = {'H', 'e', 'l', 'l', 'o', 0, 0, 0, 0, 0};
不過也不是完全相等,
因為你還是不能用
這樣子的敘述。
-
下面幾個例子中告訴我們凡是可以用指標的地方都可以用字串常數:
for (i=0; i<5; i++)
{
putchar("Hello"[i]);
putchar(*("Hello"+i));
putchar(i["Hello"]);
}
不過當然是不建議這樣子用的囉!
-
在初始化時 char x[5] = "Hello";
很容易產生執行時的錯誤,
(事實上應該說一定會產生才對)
因為字元陣列 x 內會沒有 '\0' 這個字元,
於是不管你是用 strlen(x), strcpy(y,x),...
這些函式都會無法正確地結束,
如果你是宣告為 char x[6] = "Hello"; 的話,
那就沒有問題了。
-
前面講到所有使用字元陣列指標的地方都可以用常數字串來取代,
反之,
除了在字元陣列初始化的地方之外,
任何使用字串常數的地方也都可以用 const char * 或是
char * 型態的變數來取代,
例如:
char *xptr = "This is the %d-th program\n");
printf(xptr, i);
指標陣列
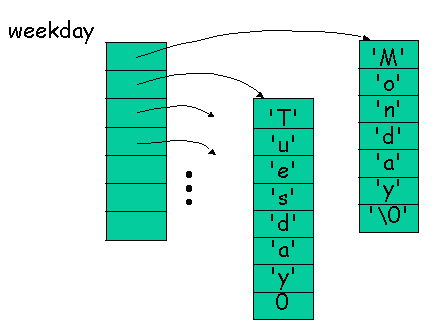
下列程式碼為一常見的指標陣列應用:
const char *weekday[7] =
{"Monday", "Tuesday", "Wednesday",
"Thursday", "Friday", "Saturday",
"Sunday"};
此變數宣告實際上只配置了七個指標的存放空間,
變數的初始化則多配置了七個字串常數,
個別為一個字元陣列,
並用這些字元陣列的第一個元素的位址來初始化 weekday[] 陣列的元素,
如下圖:
字串處理函式 (string.h, stdio.h, stdlib.h)
所謂字串處理函式是專門對字元陣列中存放的字串 (必須有結束字元 '\0')
來做處理的,
也就是說這些函式都會假定傳入的字元陣列中一定要有 '\0' 字元,
若是沒有結束字元的話,
這些函式都會出現執行時的錯誤,
無法在正確的地方結束。
常見的字串處理函式包括:
strcpy(deststr, srcstr);
strcat(deststr, srcstr);
strlen(str);
strrev(str);
printf("%s", str);
puts(str);
gets(str);
fgets(str, n, fp);
sscanf(str, "....", ....);
atoi(str);
scanf("%s", str);
注意:
-
gets(str) 函式和 fgets(str, n, fp) 函式在處理換行字元時的動作不太一樣,
gets(str) 函式會由鍵盤讀取字元直到出現 '\n' 換行字元,
並將 '\n' 以 '\0' 字元替換,
字串中容許空格字元,
fgets(str, n, fp) 函式則讀取檔案內字元直到遇見 '\n' 字元,
或是已經讀入 n-1 個字元了,
在換行字元後面補上 '\0' 字元,
或是在第 n 個字元處填入 '\0' 字元,
因此以 gets(str) 函式讀入字串時字串內不會有 '\n' 字元,
反之以 fgets(str, n, fp) 函式讀取檔案中字串時則有可能出現 '\n' 字元。
-
scanf("%s, str) 函式在運作時,
當看見格式字串內有 %s 時會認為相對應的參數是一個字元指標,
字元陣列變數 str 就是一個字元指標,
不需要再用 & 取址符號加在 str 之前。
-
gets(str) 函式與 scanf("%s", str) 函式在運作時不一樣的地方是
scanf("%s", str) 一遇見空格字元就以為字串結束了,
gets(str) 函式則不管怎樣都會讀到 '\n' 字元才停下來。
